Consistent hashing and rendezvous hashing explained.
A guide to hashing in distributed systems, including consistent hashing and rendezvous hashing.
If you are familiar with the hash table data structure you are certainly familiar with the concept of hashing. Hashing is the process of transforming an arbitrary piece of data into a fixed size value (usually an integer).
But where and why should you use hashing in a distributed system?
A first scenario is when you need to provide elastic scaling (a term used to describe dynamic addition or removal of servers based on usage load) for cache servers.
A second scenario is when you need to scale out a set of storage nodes like for example NoSQL databases.
Let's check both scenarios in details with a couple of examples.
Scaling cache servers Permalink
Let's suppose we have a system composed by multiple clients talking with multiple servers through a load balancer. So, the clients requests go to the load balancer that reroutes them to servers. The load balancer shall have a server selection strategy, something to pick each time the server to which redirect the requests.
If the requests of the clients are computationally very expensive it is reasonable using a fast in memory cache on each server. If the response to a client request is in the cache, the server can immediately return the response.
To make an effective use of caching the server selection strategy shall guarantee that all the same kind of requests will be rerouted to the same server.
Here hashing comes into play. We can hash the requests coming to the load balancer and use that hash to reroute the requests according to the hash value. For example we could hash the IP address of the client, its username or the HTTP request.
This solves the problem of mapping request to same server, but what happen when cache servers are dynamically added or removed?
Partition data across multiple servers Permalink
Let's suppose that we have a web application and you want to shard your data across multiple database servers.
There are two challenges we need to face while designing our database backend:
- how do we know on which server a particular piece of data will be stored?
- when we dynamically add/remove a database server, how do we know which data will be moved from the existing servers to the new ones? And how do we minimize data movement between servers in that case?
Once again hashing can help in this scenario. We can hash the data key and use that hash to find the database server where the data is stored. This solves the first challenge, but what happen when database servers are dynamically added or removed?
Problem Generalization Permalink
The problems described in the previous scenarios can be easily generalized. We have 3 entities
- Keys: unique identifiers for data or workload requests
- Values: data or workload requests that consume resources
- Servers: entities that manage data or workload requests
The goal is to map keys to servers while preserving three properties:
- Load Balancing: each server should be responsible for approximately the same data or load.
- Scalability: servers should be added or removed with low computational effort.
- Lookup Speed: given a key, it should be possible to efficiently identify the correct server.
Naive approach Permalink
Let's start with a simple way we can use to assign the clients requests or the data keys to the servers considering their hash value. Let's suppose we have N servers. The simplest strategy is to
- number the servers from 0 to N-1;
- calculate the hash value of the key modulo N to find a server number;
- assign the key to the server identified by that number.
This schema assigns the key always to the same server, but has a main problem: it is not horizontally scalable. If we add or remove servers from the set keeping N as reference number, the requests will continue to be routed to the removed one or will never go to the new one. If we module against the new number of servers instead, all the existing mappings get broken with the result that all existing data needs to be remapped and migrated to different servers.
This would be expensive and uncomfortable because it will either require a scheduled system downtime to update the mappings or creating read replicas to serve the queries during the migration. We need a better approach.
Consistent hashing Permalink
Let's suppose that the space of possible hash values is the range of 32 bit unsigned integers [2^32-1,0] and let's image that this space is organized in a circular way such that the last value wraps around. The consistent hashing approach requires the following steps:
Place the servers in the circular space. We use an hash function to put the initial list of servers into specific places on the circular space. For example, we can hash IP addresses of the servers to map them to different integers in the circle.
Place the keys in the circular space. We use an hash function to map each key to an integer in the circle.
Assign keys to servers. If the hash value of the key maps directly onto the same place of a server, we assign the key to that server. Otherwise, we assign the key to the first server we meet moving clockwise from the place where the key is mapped.
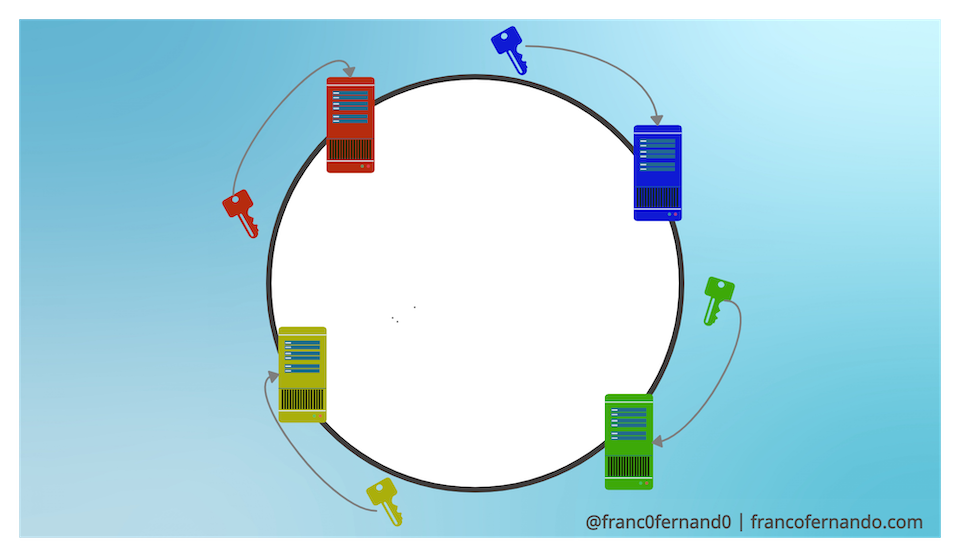
This schema works great when we need to horizontally scale our system. Indeed when a server is added or removed from the ring, only the next server on the circle is affected.
If we add another server we don't need to remap all the keys, but only the keys that are placed between the previous server in the ring and the new one. Assuming an uniform distribution of the keys on the circle, we need to remap only k/n keys on an average where k is the number of keys and n is the number of servers.
If we remove a server instead, the next server on the circle becomes responsible for all of the keys stored on the that server.
However, this scheme can still generate a non uniform load distribution between the servers.
Even if the servers were initially evenly distributed across the circle, after adding and removing some servers we can run into a situation where the server distribution across the circle is non anymore balanced. Some of the servers become responsible for a larger portion of the keys.
In reality, the issue is even more complicated because the keys don't have a perfectly uniform distribution in most cases. The non uniform distribution of the keys coupled together with non uniform distribution of the servers on the circle can lead to a situation where some servers get more easily overloaded becoming hotspots and degrading the performance of the whole system.
Virtual Nodes Permalink
The aforementioned problem can be solved introducing a number of replicas or virtual nodes for each server across the circle. This means that we use multiple hash functions to map each server into multiple places on the circular space.
The virtual nodes divide the circular space into multiple smaller ranges and each physical server is assigned to several of these smaller ranges. Virtual nodes are randomly distributed across the circle and are generally non-contiguous so that no neighboring nodes are assigned to the same physical server.
As the number of replicas or virtual nodes in the circle increase, the key distribution becomes more and more uniform. In real systems, the number of virtual nodes is very large.
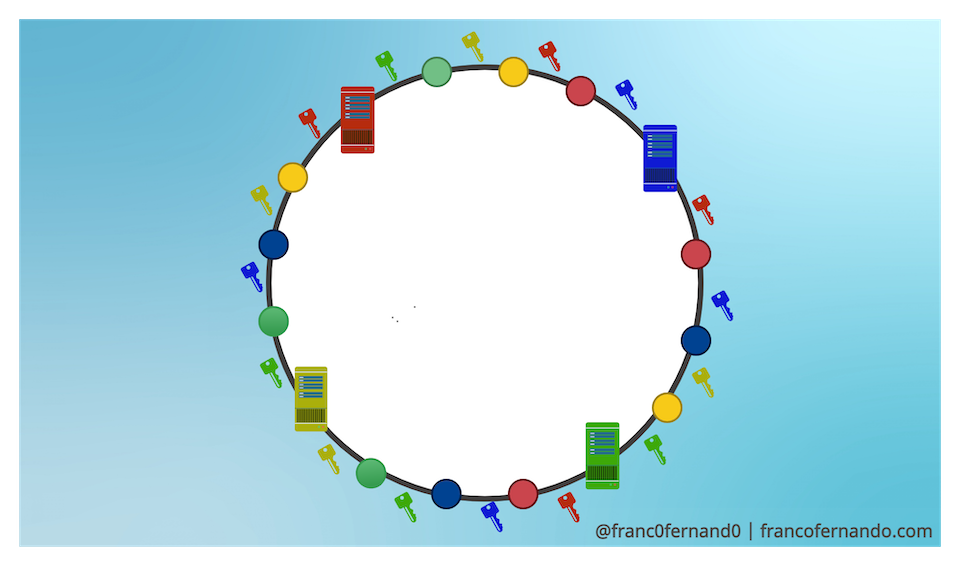
Virtual nodes not only help to avoid hotspots in the system, but they bring also the following advantages:
virtual nodes divide the hash circular space into smaller subranges, speeding up the rebalancing process after adding or removing nodes because the keys to be reassigned involves multiple physical servers instead of one.
virtual nodes can carry physical replicas of a server for fault tolerance
virtual nodes make it easier to maintain a cluster of servers made by heterogeneous machines, because it is possible to assign a higher number of virtual nodes (and hence circle subranges) to powerful servers and a lower number to less powerful servers.
Consistent Hashing in Action in Production Systems Permalink
There are a number of live systems which use consistent hashing including:
- Couchbase
- Apache Cassandra
- Amazon Dynamo
- Riak
for data partitioning and
- Akamai Content Delivery Network
- Discord Chat
for caching purposes.
Rendezvouz Hashing Permalink
Rendezvous hashing is less known hashing strategy, providing a different approach respect to consistent hashing.
The basic idea is to calculate a ranking of all the possible servers for each key using some logic. Each key is assigned to the server with highest ranking for that key.
The advantage of this strategy is clear. When adding or removing a server S, only the keys for which the S has highest ranking are affected. When removing S, the keys are assigned to the server with second highest ranking in their list. When adding S, only the keys for which S has the highest ranking are assigned to S.
Rendezvous hashing is much simpler to implement than consistent hashing in practice. You can easily get a unique list of servers for each key by hashing the key together with the server and sort the servers based on the hash values. Some simple way hashing keys and servers togheter are concatenating the key with the server or using the server ID as a hash seed.
To summarize, the rendezvous hashing approach requires three steps:
- hash all the possible key-server combinations with a hash function
- assign each key to the server with the highest hash value
- maintain the association between each key and the server with the highest hash value after adding and removing servers

Comparison between Rendezvouz and Consistent Hashing Permalink
There are 3 main things to consider when comparing rendezvouz and consistent hashing.
Query time. Consistent hashing uses typically binary search to map a key to the closest server in the circular space. So each query takes O(log(NV)) time, where N is the number of servers and V the number of virtual nodes for each server. Rendezvouz hashing takes typically O(N) because we have to calculate the hash for each key-server combination.
Memory requirements. Consistent hashing requires some fixed memory to work well in order to store the hash values for server and virtual nodes plus the mapping between servers and virtual nodes. Rendezvous hashing doesn't require storing any additional data.
Complexity. Rendezvouz hashing is easier to explain, understand and implement than consistent hashing. It provides an even distribution of the keys when adding and removing, assuming a good choice of the hash function. Consistent hashing alone (withou virtual nodes) fails to provide an even distribution of the keys especially for small clusters..
In summary, consistent hashing trades load balancing for scalability and lookup speed while rendezvous hashing provides an alternative tradeoff that emphasizes equal load balancing. Consistent hashing is more extensively used, but rendezvous hashing can be a good algorithm to load balance medium-size distributed systems, where an O(N) lookup cost is not prohibitive.
Conclusion Permalink
Consistent hashing and rendezvous hashing are great techniques used in countless distributed systems. They come in handy in many real world scenarios from elastically load balancing servers to sharding data between servers. I hope this post helped you in understanding better how these techniques are implemented and how you can use them while designing a distributed system.
If you liked this post, follow me on Twitter to get more related content daily!